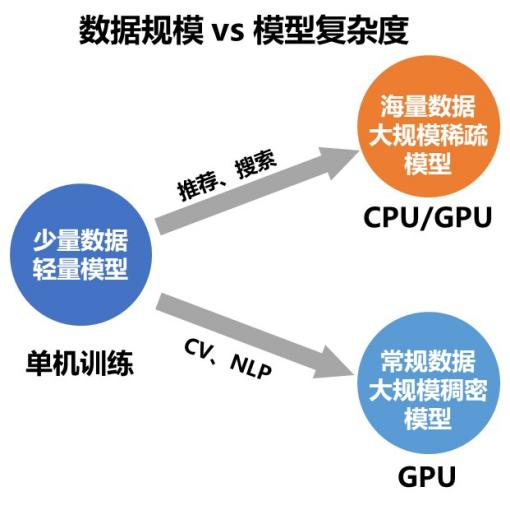
近几年,深度学习领域的开发者们对模型效果的追求愈演愈烈,各大榜单纪录不断刷新,而这个现象的背后都有着“大规模训练”的身影。简单来说,就是使用大规模的数据或大规模参数量的模型来做训练。大规模的数据可以让模型有足够的“教材”用于“学习”,而大规模的参数量则可以让模型“学习能力”更强,更容易“学习”到“教材”中的“知识”。在数据和参数规模增长的过程中,常规的单机训练由于硬件资源的限制渐渐显得捉襟见肘,而分布式训练则成为了广大开发者的必然选择。 所谓分布式训练,就是使用多台机器共同完成训练任务,这其中涉及多机任务拆分、集群训练资源配置、平衡训练速度和收敛速度、弹性训练与容错等多项重要技术,同时也是各大深度学习框架彰显技术实力的重要“战略高地”。 飞桨是我国首个开源开放、自主研发、功能完备的产业级深度学习框架,其英文名“PaddlePaddle”正是“Parallel Distributed Deep Learning”并行分布式深度学习的字母缩写组合。飞桨不仅在业内最早支持了万亿级稀疏参数模型的训练能力,而且近期又创新性的提出了 4D混合并行策略,以训练千亿级稠密参数模型,可以说分布式训练是飞桨最具特色的技术之一。那么飞桨是如何做到的呢?这与实际业务的锤炼密不可分。
图 1百度丰富业务场景 飞桨的分布式训练技术在对外提供之前就已经在百度内部广泛应用,如搜索引擎、信息流推荐、百度翻译、百度地图、好看视频、文心 ERNIE等等,既包含网络复杂、稠密参数特点的计算机视觉(CV)/自然语言处理(NLP)模型训练场景,又覆盖了有着庞大的 Embedding层模型和超大数据量的推荐搜索训练场景,可谓是分布式训练技术得天独厚的“练功房”。
图 2大规模训练场景 历经搜索推荐业务磨炼,最成熟万亿稀疏参数模型训练技术一骑绝尘 搜索推荐场景经常面临数据量大、特征维度高且稀疏化的问题。而分布式训练的参数服务器模式采用了一种将模型参数中心化管理的方式来实现模型参数的分布式存储和更新,该模式有两个角色 Server与 Worker:Worker用于执行模型的前向与反向计算;Server负责从各个 Worker收集汇总梯度并更新参数,因此对于存储超大规模模型参数的训练场景十分友好,常被用于训练拥有海量稀疏参数的搜索推荐领域模型。
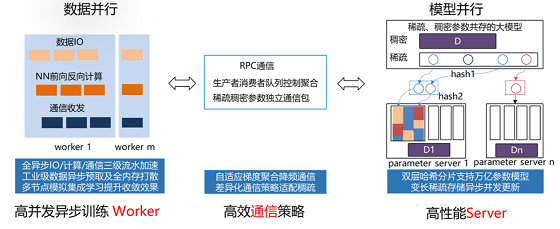
图 3传统参数服务器 百度搜索作为全球最大的中文搜索引擎,对模型的规模、性能等要求非常高。为了应对严苛的实际业务挑战,早在 2018年,飞桨的纯 CPU参数服务器模式就可以支持万亿规模稀疏参数的模型训练。之后随着模型中网络结构更加复杂,以及对训练效率和性价比的进一步追求,飞桨参数服务器技术也在更新换代:从早期 Worker节点的硬件型号必须一致的纯 CPU参数服务器到纯 GPU参数服务器,再到 CPU、GPU、其它 AI硬件混布调度训练的异构参数服务器,始终引领参数服务器技术的发展;同时也得到了更多的应用落地,如 OPPO应用商店推荐、网易云音乐主播推荐等等。 从传统纯 CPU参数服务器到纯 GPU参数服务器 传统的纯 CPU参数服务器,由高性能异步训练 Worker、高效通信策略和高性能 Server组成。通常可以使用的 CPU数量较多,训练中能够充分展示 CPU多核的吞吐量优势。在异步训练模式下训练简单模型可以极大提升数据吞吐量,整体训练速度非常出色。
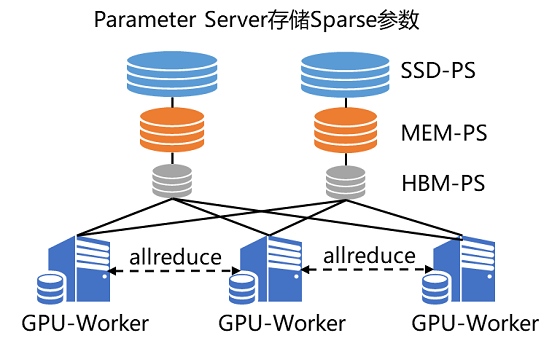
图 4传统参数服务器工作流程 但是随着模型网络越来越复杂,对算力要求越来越高,在数据量不变的情况下,CPU计算性能差的弱势就会显现,虽然可以通过增加 CPU机器数量来解决,甚至可以增加上百台,但是这种方法不仅成本大幅提高,而且集群的稳定性和扩展性也存在较大的问题。因此飞桨引入了纯 GPU参数服务器来提升计算性能,之前 100台 CPU机器才能训练的模型,仅需 1台多卡 GPU机器即可完成训练。当然,同时也要解决因为硬件更替所带来的问题。 GPU强大的算力毋庸置疑可以提升集群的计算性能,但随之而来的是,不仅模型规模会受到机器显存和内存的制约,而且通信带宽也会由于集群网卡数量降低而成为瓶颈。为了解决这两个问题,飞桨引入了两大亮点技术 SSD-MEM-HBM三级存储和 RPC&NCCL混合通信,形成了飞桨特有的纯 GPU参数服务器(PaddleBox)【1】: -SSD-MEM-HBM三级存储允许全量参数使用 SSD硬盘存储,高频参数存储于内存,当前 Batch训练所用参数使用显存,并且同时支持 SSD的参数在硬盘、内存、显存之间快速拷贝。这样通过异步流水线执行机制,隐蔽了 IO带来的额外性能开销,在保证训练速度的同时,使训练的模型大小不再受制于显存和内存,极大提升模型的规模。 -RPC&NCCL混合通信可以将部分稀疏参数采用 RPC协议跨节点通信,其余参数采用卡间 NCCL方式完成通信,充分利用带宽资源。
图 5纯 GPU参数服务器工作流程 飞桨纯 GPU参数服务器虽然解决了之前纯 CPU模式所面临的问题,但新的问题又出现了——如何提高训练资源的利用率? 从传统纯 GPU参数服务器到异构参数服务器 在纯 GPU的参数服务器下,所有的训练都在 GPU中,当模型中部分网络层比较复杂的时候,GPU利用率很难被打满,而 GPU机器中 CPU与 GPU的硬件配比是固定的,无法灵活调整。针对这种情况,有两种解决方案: -定制化 GPU机型,调整机器内 CPU与 GPU的硬件配比。 -混布 CPU和 GPU机器节点,来调整机器间的硬件配比。 基于这两种解决方案,飞桨框架 2.0版本创新性地推出了通用异构参数服务器功能。一举解除了传统参数服务器模式下,Worker节点必须严格使用同一种硬件型号的枷锁,使训练任务对硬件型号不敏感,即可以同时使用不同的硬件混合异构训练,如 CPU、AI专用芯片(如百度昆仑 XPU)以及不同型号的 GPU如 v100、P40、K40等。同时还可以解决大规模稀疏特征模型训练场景下 IO占比过高导致的芯片资源利用率过低的问题。通过异构参数服务器训练模式,用户可以在硬件异构集群中部署分布式训练任务,例如云服务器集群,高效利用不同算力芯片,为用户提供更高吞吐、更低资源消耗的训练能力。
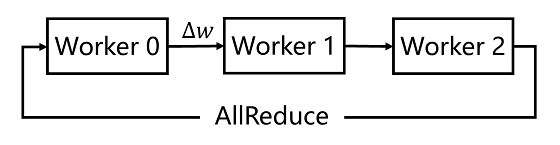
图 6异构参数服务器示意图 异构参数服务器的最大亮点是硬件感知的任务切分。如图 6所示,针对类似 ERNIE+CTR这样计算密集型与 IO密集型兼有的训练任务,可以被切分成多个子任务。其中的 IO密集型任务(如数据读取、Embedding查询)切分给 CPU机器,计算密集型任务切分给 GPU机器;用户可以根据子任务的计算复杂度来灵活决定机器配比,并且还可以兼容传统纯 CPU参数服务器和纯 GPU参数服务器所支持的训练任务。 助力文心 ERNIE快速迭代,首创 4D混合并行引领超大规模预训练潮流 在 NLP领域中,依托飞桨打造的“语义理解技术与平台文心 ERNIE”曾获得过无数殊荣:去年 3月一举拿下 SemEval 2020的 5项冠军;5月发布语言生成预训练模型 ERNIE-GEN,刷新语言生成 SOTA;6月发布多模态模型 ERNIE-ViL,刷新 5项任务纪录,登顶权威榜单 VCR;7月亮相 2020世界人工智能大会,摘取最高荣誉 SAIL奖;11月获得中国人工智能学会优秀科技成果奖。在文心 ERNIE这些闪耀成绩的背后,也有飞桨的分布式训练技术的贡献。 首先对于 NLP和 CV这类拥有复杂网络、稠密参数特点的模型,飞桨分布式训练技术的集合通信模式可以很好的支持这类模型的训练。该模式没有管理模型参数的中心节点,每个节点都是 Worker,每个 Worker负责模型训练的同时还需要掌握当前最新的全局梯度信息。集合通信模式对计算芯片的算力和芯片之间的网络互联要求较高,如高性能计算的 GPU、芯片之间的高速网络互联 NVLINK和 InfiniBand等,因此非常适合 CV和 NLP领域计算密集型训练任务。 但是在早期的集合通信架构中,多节点间的参数信息的传输通常是各个 Worker之间多次点对点通信完成的,通讯效率较低。百度在 2016年突破性地提出并使用 Ring-AllReduce多 GPU训练,通过较少的点对点通信轮数就完成了全局节点的模型参数传输,让同步并行训练的多 GPU扩展能力得到极大突破,大幅提升集合通信模式的训练速度,使这种模式在 NLP和 CV领域得到更广泛的应用。
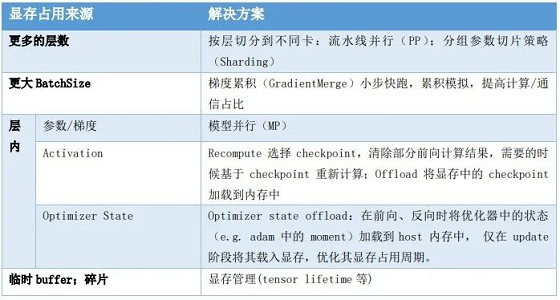
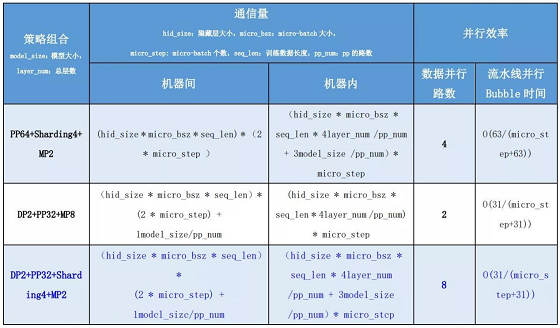
图 7集合通信训练 4D混合并行策略支持文心 ERNIE千亿语言模型训练 当前飞桨集合通信模式已经可以支持文心 ERNIE千亿语言模型的训练能力,其 Sharding-DP策略更是在近期助力文心 ERNIE的多项任务分数刷新 GLUE榜单。而这个 Sharding-DP策略正是飞桨集合通信模式为了训练 ERNIE这样的大规模复杂模型所支持的多种并行策略中的一种。那么飞桨是使用哪些策略成功支持文心 ERNIE千亿语言模型训练的呢?这些策略是如何工作的呢?接下来将为大家详细介绍。 ERNIE千亿级模型采用 100多层 Transformer网络结构,计算复杂,训练需要占用 T级显存资源,如果想用更少的机器高效训练,必须采取一系列性能优化和显存优化措施。 首先看如何性能优化。我们通过一个公式来看哪些因素可以影响训练速度,在固定的硬件环境下: 总训练速度 ∝单卡速度 *卡数 *多卡加速比 其中单卡速度由数据读取和计算速度决定;多卡加速比由计算/通信效率决定。显而易见,这三个是关键因素。除了单卡可以使用的算子融合、混合精度之类的基础性能优化策略之外,分布式训练还引入一系列并行策略。并行策略的核心思想是将数据和计算有关的图 /算子切分到不同设备上,同时尽可能降低设备间通信所需的代价,合理使用多台设备资源,实现高效的并发调度训练,最大化提升训练速度。常见并行策略有数据并行DP(Data Parallel)、Layer间并行(流水线并行 PP,Pipeline Parallel)、Layer内并行(模型并行 MP,Model Parallel)。如下表所示。我们从设备资源和计算/通信效率来分析三种策略的优缺点: 1.数据并行训练加速比最高,但要求每个设备上都备份一份模型,显存占用比较高。为此我们的改进方案是分组参数切片数据并行策略(具体原理后文介绍),兼容了 MP+DP的优势,但缺点是通信量大。 2.模型并行,通信占比高,适合在机器内做模型并行且支持的模型类型有限。 3.流水线并行,训练设备容易出现空闲状态,加速效率没有 DP高;但能减少通信边界支持更多的层数,适合在机器间使用。
其次看显存问题,通过下表分析的显存占用来源可以看出,上述的并行策略同样可以很好地应对不同来源的显存占用,更多的层数可以通过流水线并行和分组参数切分策略来解决;某层参数很大可以通过模型并行来解决;其次飞桨还提供一些其它灵活的优化方式,例如每层输出占用的显存,可以通过重计算和 Offload来解决。
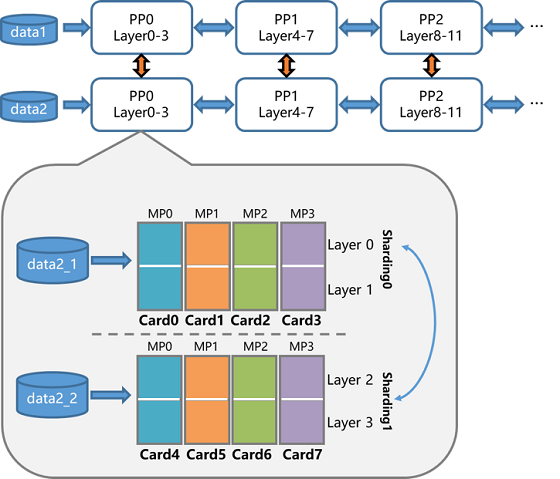
综上所述,针对性能优化和显存优化,几种并行策略都有用武之地,但是同时也有各自的局限性,所以如果想高效训练千亿模型,需要这几种策略相互组合,取长补短,发挥各自的优势。 那么如何组合呢?飞桨研发人员首先在单机内使用模型并行和分组参数切片组合的 2D策略,这么选择的原因是这两个策略通信量较大,适合使用机器内的卡间通信;然后为了承载千亿规模模型,再叠加流水线并行策略,使用多台机器共同分担;最后为了做到高效,在外层又叠加了数据并行来增加并发数量,提升整体训练速度。这样业内首个 4D混合并行策略就诞生了。
图 8 4D混合并行策略示意图 下面咱们再来简单介绍下几个并行策略的原理。 模型并行策略指的是将某一层网络切成多份,并分给不同的卡并行计算,每张卡仅需要计算部分结果。对于 ERNIE中的 Transformer网络结构,模型并行就可以对全连接层 FC切分,然后通过通信操作合并计算结果【2】。 流水线并行策略支持将模型的不同层放置到不同的设备上,通过多个设备来共同分担显存消耗,实现超大规模模型训练。相邻设备间通过通信链路传输数据。由于各个设备间传输的仅是相邻设备间的输出张量,因此通信量较小,相对来说较为适合机器间通信的场景。 值得注意的是,流水线并行可以说是广义模型并行的一种特例,本文中的模型并行仅指 Tensor切分,也就是会出现同一层网络交由不同卡来计算的情况,而流水线并行则是按照网络层的粒度切分。
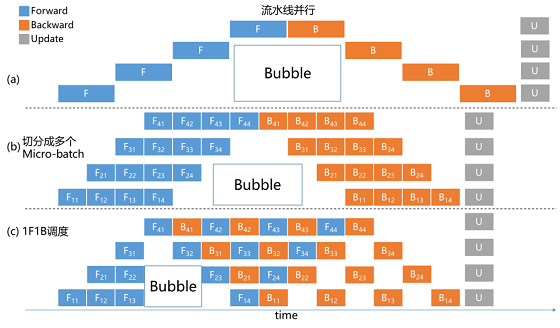
图 9流水线并行策略示意图 流水线并行策略本身也有很大的优化空间。如图 10(a)所示,优化前,任意时刻只有单个计算设备处于计算状态,其它计算设备则处于空闲状态,这个空闲时间我们称之为 Bubble时间【3】。为了减少 Bubble时间,如图 10(b)所示,飞桨进一步将 mini-batch切分成若干更小粒度的 micro-batch,每个设备依次计算单个 micro-batch的结果,从而增加了设备间的并发度,降低了流水线并行 Bubble时间比例。 此外飞桨研发人员经过对流水线并行训练过程更加深入的剖析,发现还可以进一步优化显存的利用率。采用如图 10(c)中所示的方式,在一个 micro-batch完成前向计算后,提前调度完成相应后向计算,这样就能释放部分显存,用以接纳新的数据,提升整体训练性能。使用 ERNIE模型实测,从 10(b)到 10(c),总 BatchSize可以提升 32倍,性能可以提升 9倍。
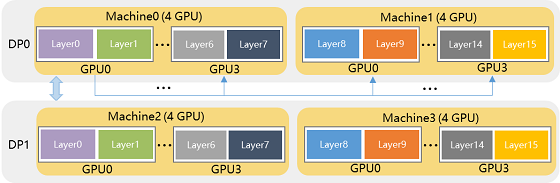
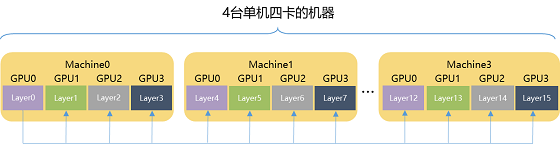
图 10流水线并行时序图 最后再来看下飞桨的分组参数切片策略,其特色是在使用参数切片方式节省显存的基础上,与数据并行策略组合成更加强大的 Sharding-DP策略。简而言之,这种组合后的策略拥有很强的灵活性,用户可以根据现有硬件环境情况,自由设定模型参数切分的数量(sharding_degree)和数据并行的路数(dp_degree),仅需要确保 sharding_degree × dp_degree =总卡数即可。 举个例子,假设用户有 4台单机四卡的机器(共 16张卡),训一个 16层网络的模型。如果模型参数规模可以使用一台机器承载,则推荐使用 dp_degree=4 & sharding_degree=4的方式,如图 11所示。这种方式的优势在于只有机器内卡间通信,但是模型最大不能超过单台机器所能承受存储范围。
图 11 dp_degree=4 & sharding_degree=4的 Sharding-DP示意图 如果模型大小超过了单台机器,问题也不大,用户可以灵活地选择 dp_degree=2 & sharding_degree=8方式,如图 12所示。与上一种方式相比,这种方式支持的模型参数规模翻倍。
图 12 dp_degree=2 & sharding_degree=8的 Sharding-DP示意图 但是在一些特殊的情况下,如果模型参数规模非常大,半数机器都无法承载,则可以进一步使用 dp_degree=1 & sharding_degree=16方式,即将整个模型参数交由全部机器承载,这也是标准的 ZeRO-DP【4】方式,如图 11所示。这种方式跨机器通信数非常高,对训练速度影响很大。其实 Sharding-DP可以说是 ZeRO-DP的一种升华,让用户可以使用更加高效方式应对特殊场景之外的绝大部分训练任务。
图 13 dp_degree=1 & sharding_degree=16的 Sharding-DP示意图示意图 最后我们从理论性能角度对比分析了几组混合并行策略,即 DP2+PP32+Sharding2+MP4、PP64+Sharding2+MP4和 DP2+PP32+MP8。如下表所示,与两种 3D方式相比,4D混合并行策略在通信量和 Bubble时间上并未明显增长(具体公式推导和示例请参见相关教程【5】),但是大幅提升了数据并行路数!
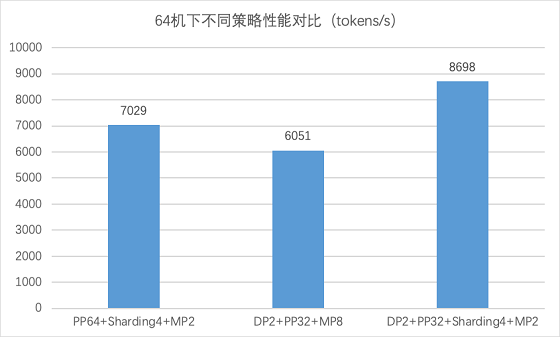
测试验证 从上面理论分析上来看,4D混合并行策略应该会具有更好的性能。那么实际效果如何呢?咱们进入实测阶段。我们使用 64台 8卡 GPU v100机器的环境来验证不同策略组合的训练效果,而测试的对象,正是拥有 2300亿参数规模的“重量级”ERNIE模型。测试后我们可以看到 4D混合并行策略训练速度高于其它两种 3D混合并行策略,达到了8698 tokens/s,至少可以提速 23.7%。
自飞桨设计之初就开始潜心研究分布式训练技术以应对大规模参数模型的训练任务。在丰富的搜索推荐业务的驱动下,飞桨分布式训练参数服务器模式历经三代。最早的纯 CPU参数服务器就已经可以训练万亿级规模的稀疏参数模型。其后随着业务的需要以及前沿技术的发展,产生了计算能力更强的纯 GPU参数服务器模式。最近新推出的业内首创的异构参数服务器模式,支持场景更多而且可以极大地提升硬件资源利用效率。对于大规模稠密参数模型,飞桨分布式训练技术同样与业务紧密结合,其集合通信模式通过最新的 4D混合并行策略,支持了 2300亿参数规模的文心 ERNIE模型的分布式训练。如今飞桨已经开始研究下一代分布式技术,来同时兼容超大规模稠密参数和稀疏参数模型的训练。相信在实际产业应用这个核心驱动力推动下,飞桨分布式训练必将成为星辰大海上的那颗北极星,为广大开发者们指引航向。 【1】Zhao W, Xie D, Jia R, et al. Distributed hierarchical gpu parameter server for massive scale deep learning ads systems[J]. arXiv preprint arXiv:2003.05622, 2020 【2】Shoeybi M, Patwary M, Puri R, et al. Megatron-lm: Training multi-billion parameter language models using model parallelism[J]. arXiv preprint arXiv:1909.08053, 2019. 【3】Huang Y, Cheng Y, Bapna A, et al. Gpipe: Efficient training of giant neural networks using pipeline parallelism[J]. arXiv preprint arXiv:1811.06965, 2018. 【4】Rajbhandari S, Rasley J, Ruwase O, et al. Zero: Memory optimizations toward training trillion parameter models[C]//SC20: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 2020: 1-16. 【5】相关教程:https://fleet-x.readthedocs.io/en/latest/paddle_fleet_rst/collective/collective_mp/hybrid_parallelism.html |