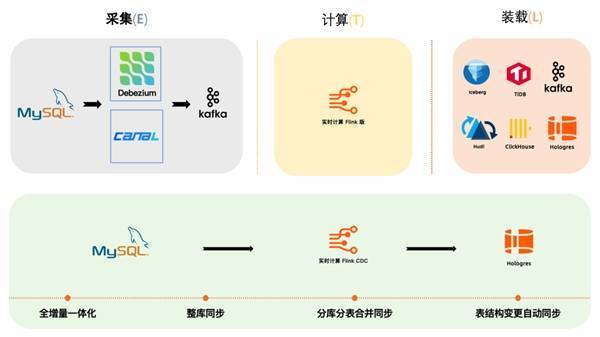
作者|徐榜江 余文兵 赵红梅 随着大数据的迅猛发展,企业越来越重视数据的价值,这就意味着需要数据尽快到达企业分析决策人员,以最大化发挥数据价值。企业最常见的做法就是通过构建实时数仓来满足对数据的快速探索。在业务建设过程中,实时数仓需要支持数据实时写入与更新、业务敏捷快速响应、数据自助分析、运维操作便捷、云原生弹性扩缩容等一系列需求,而这就依赖一个强大的实时数仓解决方案。阿里云实时计算 Flink 版(以下简称“阿里云 Flink”)提供全增量一体化数据同步技术、强大的流式 ETL 等能力,支持海量数据实时入仓入湖。阿里云 Hologres 作为新一代实时数仓引擎能同时解决 OLAP 多维分析、在线服务、离线数据加速等多个业务查询场景,通过阿里云 Flink 与 Hologres 的强强结合,实现全链路的数据探索实时化、数据分析敏捷化,快速助力业务构建企业级一站式实时数仓,实现更具时效更智能的业务决策。 在本文中,我们将会介绍阿里云 Flink、阿里云 Hologres 在构建实时数仓上所具备的核心能力以及二者结合的最佳解决方案,用户通过阿里云 Flink+Hologres 实时数仓解决方案,可以显著降低数仓建设门槛,让数据发挥更大的价值,助力各行各业实现数字化升级。 Flink CDC 核心能力Apache Flink 是开源的大数据流式计算引擎,支持处理数据库、Binlog、在线日志等多种实时数据,提供端到端亚秒级实时数据分析能力,并通过标准 SQL 降低实时业务开发门槛。伴随着实时化浪潮的发展和深化,Flink 已逐步演进为流处理的领军角色和事实标准,并蝉联 Apache 社区最活跃项目。 Flink CDC 是阿里云计算平台事业部 2020 年 7 月开源的一款数据集成框架,与 Flink 生态深度融合,具有全增量一体化、无锁读取、并发读取、分布式架构等技术优势,既可以替代传统的 DataX 和 Canal 工具做数据同步,也支持数据库数据实时入湖入仓,同时还具备强大的数据加工能力。 在构建实时数仓的过程中,数据采集是必需的组件。在传统的 ETL 架构里,采集层国外用户通常选择 Debezium,国内用户则习惯用 DataX 和 Canal,采集工具负责采集数据库的全量数据和增量数据。采集到的数据会输出到消息中间件如 Kafka,然后通过 Flink 计算引擎实时消费消息中间件数据做计算层的数据清洗和数据加工,加工完成后再写入目的端(装载层),通常是各种数据库、数据湖和数据仓库。在传统 ETL 链路中,数据采集工具与消息队列是比较重的组件,可能维护在不同的团队,在上游的数据源有业务变更或者这些组件需要升级维护时,整个链路的维护成本会非常大。
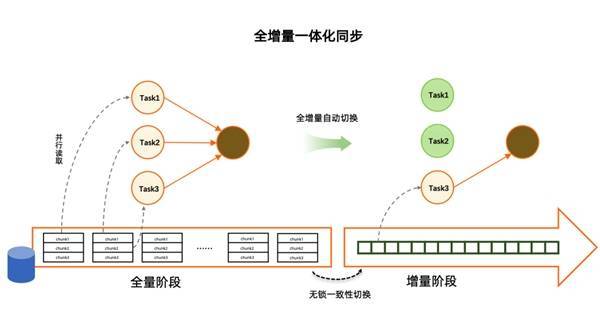
通过使用 Flink CDC 去替换上图中的数据采集组件与消息队列,将采集层(Extraction)和计算层(Transformation)合并,简化了整个 ETL 分析链路,用户可以使用更少的组件完成数据链路的搭建,整体架构带来更低的运维开销和更少的硬件成本、更好的数据链路稳定性、以及降低端到端的数据延迟。除了稳定性的提升,Flink CDC 的另一个优势就是用户只需要写 SQL 脚本就能完成 CDC 数据的清洗,加工和同步,极大地降低了用户使用门槛。 除全增量一体化同步能力外,阿里云 Flink CDC 还提供了表结构变更自动同步、整库同步、分库分表合并同步等诸多企业级特性,方便用户快速打通数据孤岛,实现业务价值。 1.1 全增量一体化同步 Flink CDC 通过增量快照读取算法在开源数据集成领域率先支持了无锁读取、并行读取、断点续传、不丢不重四个重要特性。其中无锁读取彻底解决了数据同步对上游业务数据库的死锁风险,并行读取很好地满足了海量数据同步的需求,断点续传和不丢不重特性则是提升了同步链路的稳定性和可靠性。
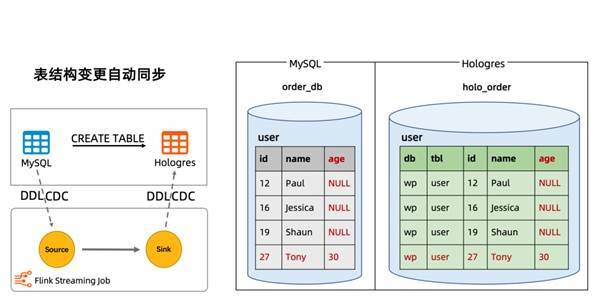
增量快照读取算法的核心思路就是在全量读取阶段把表分成一个个 chunk 进行并发读取,在进入增量阶段后只需要一个 task 进行单并发读取 Binlog 日志,在全量和增量自动切换时,通过无锁算法保障一致性。这种设计在提高读取效率的同时,进一步节约了资源,实现了全增量一体化的数据同步。配合阿里云实时计算产品提供的资源自动调优特性,Flink CDC 作业的资源可以做到自动扩缩容,无需手动介入。 1.2 表结构变更自动同步 随着业务的迭代和发展,数据源的表结构变更是经常会发生的操作。用户需要及时地去修改数据同步作业以适配最新的表结构,这一方面带来了较大的运维成本,也影响了同步管道的稳定性和数据的时效性。阿里云 Flink 支持通过 Catalog 来实现元数据的自动发现和管理,配合 CTAS (Create Table AS)语法,用户可以通过一行 SQL 实现数据的同步和表结构变更自动同步。 Flink SQL> USE CATALOG holo; Flink SQL> CREATE TABLE user AS TABLE mysql.`order_db`.`user`; CTAS 语句会解析成一个 Flink 作业执行,这个 Flink 作业源头支持读取数据变更和表结构变更并同步到下游,数据和表结构变更都可以保证顺序,上述 CTAS 语句运行时结构变更同步的效果如下图所示。
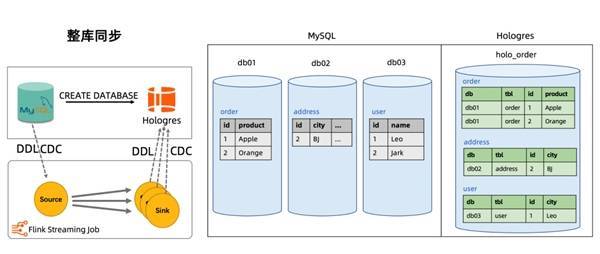
示例如果在上游 MySQL 的 user 表中新增一列 age,并插入一条 id 为 27,年龄为 30 的记录。 MySQL> ALTER TABLE `user` ADD COLUMN `age` INT; MySQL> INSERT INTO `user` (id, name, age) VALUES (27, 'Tony', 30); user 表上的数据和结构变更都能实时地自动同步到下游 Hologres 的 user 表中,id 为 12,16 和 19 的历史数据,新增的列会自动补 NULL 值。 1.3 整库同步 在实时数仓构建中,用户经常需要将整个数据库同步到数仓中做进一步的分析,一张表一个同步作业的方式不但浪费资源,也会给上游数据库产生较大的压力。针对这类用户痛点,阿里云 Flink CDC 提供了整库同步特性。整库同步功能通过 CDAS (Create Database AS) 语法配合 Catalog 实现。 Flink SQL> USE CATALOG holo; Flink SQL> CREATE DATABASE holo_order AS DATABASE mysql.`order_db` INCLUDING ALL TABLES; 例如 MySQL Catalog 和 Hologres Catalog 配合 CDAS 语法,可以完成 MySQL 到 Hologres 的全增量数据同步。CDAS 语句会解析成一个 Flink 作业执行,这个 Flink 作业自动解析源表的表结构及相应的参数,并将指定的一个或多个数据库同步到下游 Hologres 数仓中,整个过程用户无需手写 DDL 语句,无需用户在 Hologres 提前创建表,就能快速实现数据的整库同步。
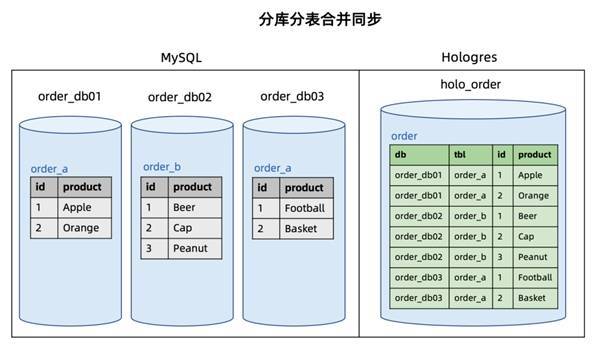
CDAS 作业默认提供表结构变更同步能力,所有表的结构变更都会按照发生顺序同步至下游 Hologres 实时数仓,CDAS 语法也支持过滤不需要同步的表。 1.4 分库分表合并同步 分库分表是高并发业务系统采用的经典数据库设计,通常我们需要将分库分表的业务数据汇聚到一张数仓中的大表,方便后续的数据分析,即分库分表合并同步的场景。针对这种场景,阿里云 Flink CDC 提供了分库分表合并同步特性,通过在 CTAS 语法支持源库和源表的正则表达式,源数据库的分表可以高效地合并同步到下游 Hologres 数仓中。 Flink SQL> USE CATALOG holo; Flink SQL> CREATE TABLE order AS TABLE mysql.`order_db.*`.`order_.*`; 述 CTAS 语句中的源库名 order_db.* 是个正则表达式,可以匹配当前 MySQL 实例下的 order_db01,order_db02 和 order_db03 三个库,源表名 order* 也是个正则表达式,可以匹配三个库下所有以 order打头的表。
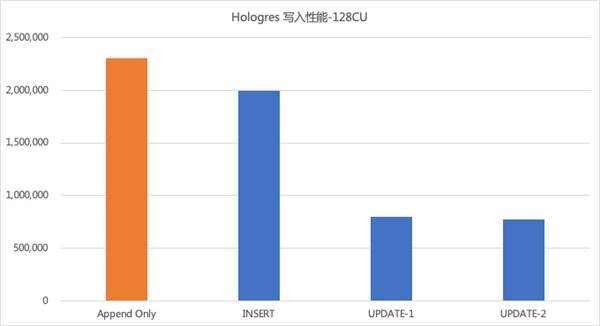
针对分库分表同步场景,用户只需要提供分库分表的正则表达式就可以将这多张分库分表合并同步到下游 Hologres 数仓的 ordder 表中。与其他 CDAS 语句一样,分库分表同步场景默认提供表结构变更自动同步特性,下游 Hologres 表的 schema 为所有分表合并后的最宽 schema。分库分表同步时每行记录所属的库名和表名会作为额外的两个字段自动写入到 user 表中,库名(上图中 db 列)、表名(上图中 tbl 列)和原主键(上图中 id 列) 会一起作为下游 Hologres user 表的联合主键,保证 Hologres user 表上主键的唯一性。 Hologres 核心能力阿里云 Hologres 是自研的一站式实时数据仓库引擎,支持海量数据实时写入、实时更新、实时分析,支持标准 SQL(兼容 PostgreSQL 协议),提供 PB 级数据多维分析(OLAP)与即席分析以及高并发低延迟的在线数据服务(Serving),与阿里云 Flink、MaxCompute、DataWorks 等深度融合,为企业提供离在线一体化全栈数仓解决方案。 2.1 高性能实时写入与更新 数据写入的时效性是实时数仓的重要能力之一。对于 BI 类等延迟不敏感的业务查询,如果写入时延几秒甚至几分钟可能是可以接受的。而对于很多生产系统,如实时风控、实时大屏等场景,要求数据写入即可见。如果写入出现延迟,就会查询不到最新的数据,严重影响线上业务决策。在实时数仓整个数据处理链路中,Hologres 作为一站式实时数据仓库引擎,提供海量数据高性能的实时写入,数据写入即可查询,无延迟。 同时在数仓场景上,数据来源复杂,会涉及到非常多的数据更新、修正的场景,Hologres 可以通过主键(Primary Key, PK)提供高性能的 Upsert 能力,整个写入和更新过程确保 Exactly Once,满足对对数据的合并、更新等需求。 下图为 Hologres 128C 实例下,10 个并发实时写入 20 列的列存表的测试结果。其中竖轴表示每秒写入记录数,横轴为 4 个写入场景:
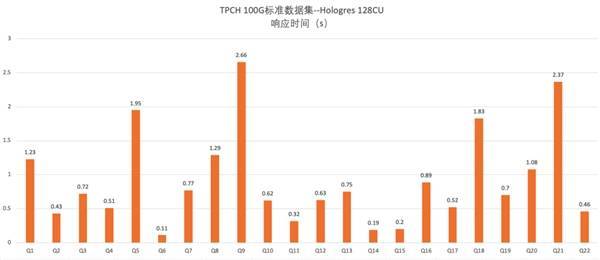
● Append Only:写入表无主键,写入能力 230 万+的 RPS。 ● INSERT:写入表有主键,如果主键冲突就丢弃新行,写入能力 200 万 RPS。 ● UPDATE-1:写入表有主键,表中原始数据量为 2 亿,按照主键 Upsert,写入能力 80 万的 RPS。 ● UPDATE-2:写入表有主键,表中数据量为 20 亿,按照主键做 Upsert,写入能力 70 万的 RPS。 2.2 实时 OLAP 分析 Hologres 采用可扩展的 MPP 全并行计算,支持行存、列存、行列共存等多种存储模式,同时支持多种索引类型。通过分布式处理 SQL 以及向量化的算子,能够将 CPU 资源发挥到极致,从而支持海量数据亚秒级分析,无需预计算,就能支持实时多维分析、即席分析等多种实时 OLAP 分析的场景,再直接无缝对接上层应用/服务,满足所见即所得的分析体验。 下图为 Hologres 128C 实例下,TPCH 100G 标准数据集下的测试结果,横轴表示 query,纵轴是响应时间:
2.3 高性能在线服务 随着实时数仓的广泛应用,越来越多的企业把实时数仓作为在线服务系统提供在线查询。Hologres 作为 HSAP(Hybrid Serving and Analytics Processing, 服务与分析一体化)的最佳落地实践,除了具备处理分析型 Query 的能力外,还具备十分强大的在线服务 Serving 能力(高 QPS 点查),例如 KV 点查与向量检索。在 KV 点查场景中,Holgres 通过 SQL 接口可以支持百万级的 QPS 吞吐与极低的延时。通过 Hologres 能够做到一套系统、一份数据支持同时 OLAP 分析和在线服务两种场景,简化数据架构。 下图为 Hologres 128C 实例下,CPU 消耗 25%的点查测试性能:
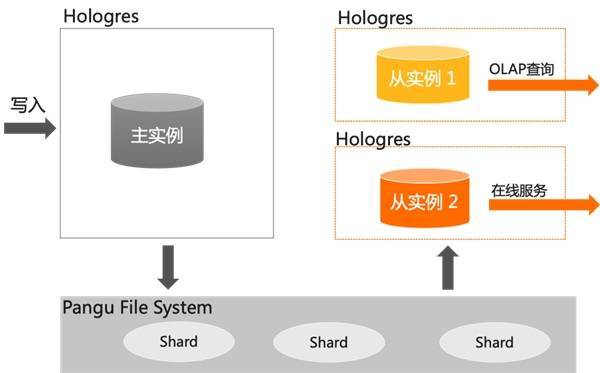
2.4 读写分离高可用 实时数据仓库 Hologres 提供高 QPS 低延迟的写入能力,支持在线服务的查询场景,还支持复杂的多维分析 OLAP 查询。当不同类型,不同复杂的任务请求到 Hologres 实例上时,Hologres 不仅需要确保任务的正常运行,还要确保系统的稳定性。当前 Hologres 支持通过共享存储的一主多从子实例的高可用架构,实现了完整的读写分离功能,保障 不同业务场景的 SLA。
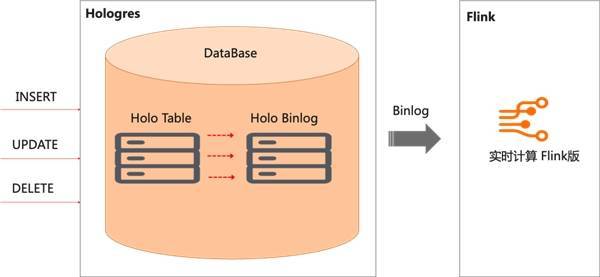
读写分离:实现了完整的读写分离功能,保障不同业务场景的 SLA,在高吞吐的数据写入和复杂的 ETL 作业、OLAP 查询、AdHoc 查询、在线服务等场景中,系统负载物理上完全隔离,不会因写入任务产生了查询任务的抖动。多类型负载资源隔离:一个主实例可以配置四个只读实例,实例之间可以根据业务情况配置不同规格,系统负载物理上完全隔离,避免相互影响而带来抖动。实例间数据毫秒级异步同步延迟:P99 5ms 内。 2.5 Binlog 订阅 类似于传统数据库 MySQL 中的 Binlog 概念,Binlog 用来记录数据库中表数据的修改记录,比如 Insert/Delete/Update 的操作。在 Hologres 中,表的 Binlog 是一种强 Schema 格式的数据,Binlog 记录的序列号(BigInt),在单 shard 内单调递增,类似于 Kafka 中的 Offset 概念。通过阿里云 Flink 消费 Hologres Binlog,可以实现数仓分层间的全链路实时开发,在分层治理的前提下,缩短数据加工端到端延迟,同时提升实时数仓分层的开发效率。
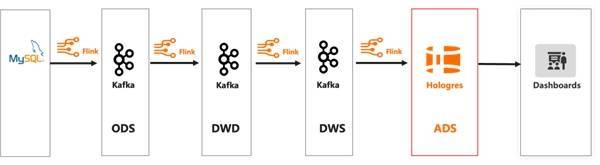
阿里云 Flink x Hologres 一站式企业级实时数仓解决方案3.1 实时数仓 ETL ETL( Extract-Transform-Load)是比较传统的数据仓库建设方法,业务库的数据 Binlog 经过阿里云 Flink 的 ETL 处理之后,数据写入到实时数仓 Hologres 中,然后进行各类数据查询分析。ETL 的方法核心是需要在数仓中具备完善的数仓模型分层,通常按照 ODS(Operational Data Source)> DWD(Data Warehouse Detail)> DWS(Data Warehouse Summary)> ADS(Application Data Service)分层,整个数仓链路比较完善。
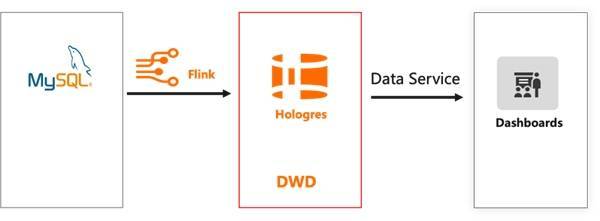
在这个链路中,需要将数据源比如 MySQL 的 Binlog 数据通过阿里云 Flink CDC 同步到消息队列 Kafka,再通过阿里云 Flink 将 ODS 的数据进行过滤,清洗,逻辑转化等操作,形成对不同的业务主题模型的 DWD 数据明细层,同时将数据发送到 Kafka 集群,之后再通过阿里云 Flink 将 DWD 的数据进行轻度的汇总操作,形成业务上更加方便查询的 DWS 轻度汇总层数据,再将数据写入 Kafka 集群。最后再面向业务具体的应用层的需求,在 DWS 层基础上通过阿里云 Flink 实时处理形成 ADS 数据应用层,写入实时数仓 Hologres 进行存储和分析,支持业务各种不同类型的报表,画像等业务场景。 实时数仓 ETL 的处理优点是数仓各种层次比较完备,职责清晰,但是缺点是 Flink 结合 Kafka 集群维护复杂,处理链路比较长,历史数据修正复杂,ADS 应用层的数据实时性会弱,其次数据在各个 Kafka 中不便于查询,不便于检查数据质量,也不便于实现 schema 的动态变化。 3.2 实时数仓 ELT 随着业务对数据的时效性要求越来越高时,相较于 ETL 复杂繁杂的处理链路,业务需要更快速的将数据实时入仓,因此 ELT 变成了比较流行的处理方法。ELT 是英文 Extract-Load-Transform 的缩写,我们可将 ELT 理解为一个数据迁移集成的过程。在这个过程中,我们可以对数据源关系型数据库比如 MySQL、PostgresSQL 和非关系型数据库比如 HBase、Cassandra 等业务库的 Binlog,消息队列比如 Datahub、Kafka 中的埋点采集日志等数据,经过阿里云 Flink 实时抽取,然后加载到 Hologres 中进行相关的 OLAP 分析和在线服务。 在这个链路中,阿里云 Flink 负责数据的实时入仓以及数据的清洗关联,清洗后的数据实时写入 Hologres,由 Hologres 直接存储明细数据。在 Hologres 中可以简化分层,以明细层为主,按需搭配其他汇总层,通过 Hologres 强大的数据处理能力直接对接报表、应用等上层查询服务。上层的分析 SQL 无法固化,通常在 ADS 层以逻辑视图(View)封装 SQL 逻辑,上层应用直接查询封装好的 View,实现即席查询。
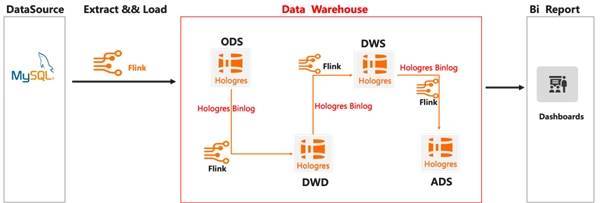
实时数仓中采取 ELT 的方式进行建设,会给数据和业务带来比较大的收益,详细如下: ● 灵活性:将原始的业务数据直接入仓,形成 ODS 层的数据,在数仓中通过 View 可以灵活地对数据进行转换(Transformation)的处理,View 可以随时根据业务进行调整。 ● 成本低:数据仓库的架构比较清晰,链路比较短,运维成本比较低。 ● 指标修正简单:上层都是 View 逻辑封装,只需要更新底表的数据即可,无需逐层修正数据。 但是该方案也存在一些缺点,当 View 的逻辑较为复杂,数据量较多时,查询性能较低。因此比较适合于数据来源于数据库和埋点系统,对 QPS 要求不高,对灵活性要求比较高,且计算资源较为充足的场景。 3.3 实时数仓分层(Streaming Warehouse 方案) 按照传统数仓的开发方法论,采用 ODS>DWD>DWS>ADS 开发的方法,通过阿里云 Flink 和 Hologres Binlog 的组合关系,支持层与层之间有状态的全链路事件实时驱动。在该方案中,数据通过阿里云 Flink CDC 实时入仓至 Hologres,再通过阿里云 Flink 订阅 Hologres Binlog,实现数据在不同层次之间的连续加工,最后写入 Hologres 对接应用查询。 通过这个方案,Hologres 可以达到像 Kafka、Datahub 等消息队列同等的能力,增加数据复用的能力,一个 Table 的数据既可以提供给下游阿里云 Flink 任务消费,还可以对接上游 OLAP/在线服务查询,不仅节省了成本,还简化数仓架构,同时也让数仓中的每一个层次都可以实时构建、实时查询,提升数据的流转效率。
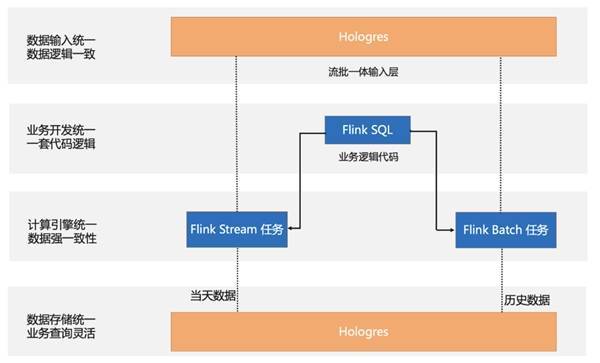
3.4 流批一体数仓 在实时数仓中,流计算任务和批处理任务都是分两条工作流进行开发的,也即是 Kappa 架构模式。在这套数仓架构中,会存在人力成本过高,数据链路冗余,数据口径不一致,开发效率低下的一些问题。 为了解决这些问题,阿里云 Flink+Hologres 提供了流批一体的能力。在该场景中,将输入层统一变成 Hologres,通过一套业务逻辑代码达到流和批处理的能力,其中 Flink SQL 的 Stream 任务消费 Hologres Binlog 提供流式处理,Flink SQL 的 Batch 任务读取 Hologres 表的原始数据达到批处理能力,经过 Flink 统一的计算处理之后,统一写入存储至 Hologres。 阿里云 Flink 结合 Hologres 的流批一体技术,统一了数据输入层、实时离线计算层和数据分析存储层,极大的提升了数据开发的效率,保证了数据的质量。
|