作者:石玉阳 人力家 高级数据研发工程师 业务简介人力家是由阿里钉钉和人力窝共同投资成立,帮助客户进入人力资源数字化,依靠产品技术创新驱动战略的互联网公司。公司主要提供包括人事管理、薪酬管理、社保管理、增值服务在内的人力资源SaaS服务,加速对人力资源领域赋能,实现人力资源新工作方式。目前已服务电子商务、零售服务等领域的多行业客户。 人力家是一家典型的创业公司,目前处于一个竞争激烈的市场环境中,公司具有多产品性质,每个产品的数据具有独立性,同时为了配合内部CRM数据需求,更好地把数据整合,对于数仓团队来说是一个不小的挑战,对于数仓团队要求的是稳,准,及时响应。需要数仓团队既要满足内部的数据需求,也需要在计算的成本上实现优化。 业务痛点MaxCompute作为一款优秀的大数据产品,其不仅可以高性价比分析处理海量数据,同时MaxCompute支持开发接口和生态,为数据、应用迁移、二次开发提供灵活性。QuickBI可以直连MaxCompute产出报表数据供公司内部分析、统计、决策。因为公司开通的MaxCompute是按量付费规格,所以计算任务和QuickBI 报表每次不同的查询都会耗费计算资源导致MaxCompute计算费用增加,在过去的一段时间,MaxCompute每个月的成本波动较大,不符合期望值,且不能有效、及时的发现一些高成本sql和多频访问报表数据集。 具体原因分析分析 MaxCompute 账单发现费用波动是因为大计算任务和QuickBI报表数据集的自定义sql,主要为以下五点。 1、单SQL查询费用较高MaxCompute计算和部分QuickBI报表按照时间维度来进行查询数据,但是有些时间查询跨度较大,或者基表数据量大从而形成一条大查询sql。 2、分区不合理部分MaxCompute计算逻辑和报表数据集设置不合理,有些查询是直接查询近3年分区的数据, 造成计算成本费用增加。 3、报表访问频率高,筛选项不同部分QuickBI报表的数据集成本其实很低,但是每天访问的次数确实很大,由于重复执行造成MaxCompute计算作业量增加,从而导致计算费用增加。 4、兼容报表增加维表数据部分报表数据集为了兼容数据产出,需要增加部分维表数据来进行关联,但有些维表数据集其实很大,最后也会形成一条大查询sql。 5、运行时间较长MaxCompute部分计算sql和QuickBI报表数据集计算时间较长,影响整体业务运行时间和报表数据产出。 基于Information Schema分析项目作业MaxCompute元数据服务Information Schema提供了项目元数据及使用历史数据等信息。在ANSI SQL-92的Information Schema基础上,添加了面向MaxCompute服务特有的字段及视图。 租户级别Information Schema是原项目级别Information Schema的升级版,是在每个阿里云账号下创建名为SYSTEM_CATALOG的项目,并内置Information Schema,通过访问该内置Schema提供的只读视图,查询当前用户所有项目的元数据信息以及使用历史信息。元数据视图列表如下 
对于以上部分视图元数据信息,我们更关心的是Information_Schema.TASKS_HISTORY表中每日任务计算的时间、成本和次数。 分析SQL脚本这里我们使用的是租户级别的 Information Schema,相比于项目级别的 Information Schema,租户级别的只需要创建一个计算节点就可以计算所有 project 的任务,而项目级别的 Information Schema 每个 project 都需要一个计算节点,这里更推荐租户级别的 Information Schema。 set odps.namespace.schema=true;
set odps.sql.decimal.odps2=true;
create table if not exists ads_project_cost_pay_di
(
env_type string comment '环境类型'
,cost_type string comment '消费类型'
,inst_id string comment '唯一id,作业id'
,owner_name string comment '作业所属人'
,task_type string comment '作业类型 SQL:SQL作业 CUPID:Spark或Mars作业 SQLCost:SQL预估作业 SQLRT:查询加速SQL作业 LOT:MapReduce作业 PS:PAI的Parameter Server AlgoTask:机器学习作业'
,input_records string comment '作业输入的records数目'
,output_records string comment '作业输出的records数目'
,input_bytes string comment '实际扫描的数据量,与Logview相同。'
,output_bytes string comment '输出字节数。'
,status string comment '数据采集瞬间的运行状态(非实时状态)。包含以下状态:Terminated:作业已执行结束。Failed:作业失败。 Cancelled:作业被取消。'
,cost_pay DECIMAL(18,5) comment '费用 单位元'
,complexity string comment '任务复杂度'
,settings string comment '上层调度或用户传入的信息,以JSON格式存储。包含字段:USERAGENT、BIZID、SKYNET_ID和SKYNET_NODENAME。'
,sql_script string comment 'sql 代码'
,start_time string comment '开始时间'
,end_time string comment '结束时间'
,data_collection string comment 'quickbi数据集'
)
comment 'odps 费用 明细'
partitioned by (ds string comment '分区')
;
insert overwrite table ads_project_cost_pay_di partition(ds=${bizdate})
select case when task_catalog = 'renlijia_ng' then '生产'
when task_catalog = 'renlijia_ng_dev' then '测试'
else task_catalog
end as env_type
,if(regexp_count(settings,'quickbi')>0,'quickbi',task_catalog)cost_type
,inst_id
,owner_name
,task_type
,input_records
,output_records
,input_bytes
,output_bytes
,status
,nvl(case when task_type = 'SQL' then cast(input_bytes/1024/1024/1024 * complexity * 0.3 as DECIMAL(18,5) )
when task_type = 'SQLRT' then cast(input_bytes/1024/1024/1024 * complexity * 0.3 as DECIMAL(18,5) )
when task_type = 'CUPID' and status='Terminated'then cast(cost_cpu/100/3600 * 0.66 as DECIMAL(18,5) )
else 0
end,0) cost_pay
,complexity
,settings
,operation_text sql_script
,start_time
,end_time
,regexp_extract(operation_text,'(?<=quickbi=).*?(?==quickbi)',0)data_collection
from SYSTEM_CATALOG.INFORMATION_SCHEMA.TASKS_HISTORY where ds=${bizdate};
注:sql成本计算公式(官方示例): case
when task_type = 'SQL' then cast(input_bytes/1024/1024/1024 * complexity * 0.3 as DECIMAL(18,5) )
when task_type = 'SQLRT' then cast(input_bytes/1024/1024/1024 * complexity * 0.3 as DECIMAL(18,5) )
when task_type = 'CUPID' and status='Terminated'then cast(cost_cpu/100/3600 * 0.66 as DECIMAL(18,5) )
else 0
end;
治理前后MaxCompute整体成本对比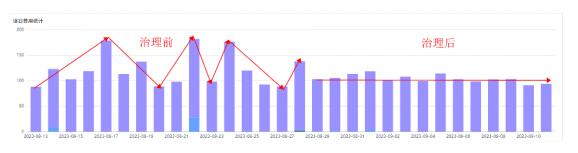
报表产出明细数据因为公司是按量付费的MaxCompute,所有我们主要关心的是成本问题和报表的访问情况。对此我们主要从环境、数据集、用户等维度进行分析。 QuickBI数据集(查ads_project_cost_pay_di表) 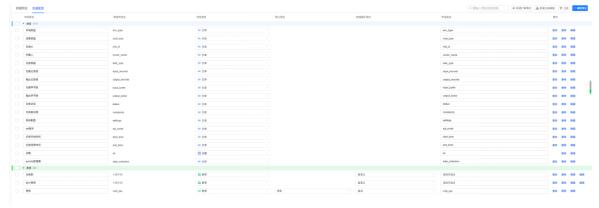
QuickBI报表Demo 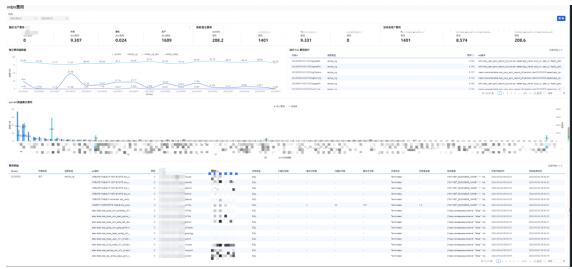
QuickBI数据集字段是从sql-script中正则匹配出来,且QuickBI数据集需要单独增加一个字段用来抽取数据集名。 1、手动在QuickBI数据集增加如下字段: ‘quickbi=xxx数据集=quickbi’ as 数据集自定义字段
2、利用MaxCompute函数regexp_extract按照如下方式正则匹配: regexp_extract(operation_text,'(?<=quickbi=).*?(?==quickbi)',0)
分析改进项:1、替换分区不合理数据表或数据集。 2、维表数据在上层加工,下层减少依赖项,做到最好只查一张表。 3、高频访问数据集优化存储大小和QuickBI 报表仪表盘数量。 4、减少报表产出时间。 综上:借助MaxCompute 租户级别Information Schema,拉取每日历史作业信息,公司成功把每日MaxCompute成本降低到合理波动区间。 | 








