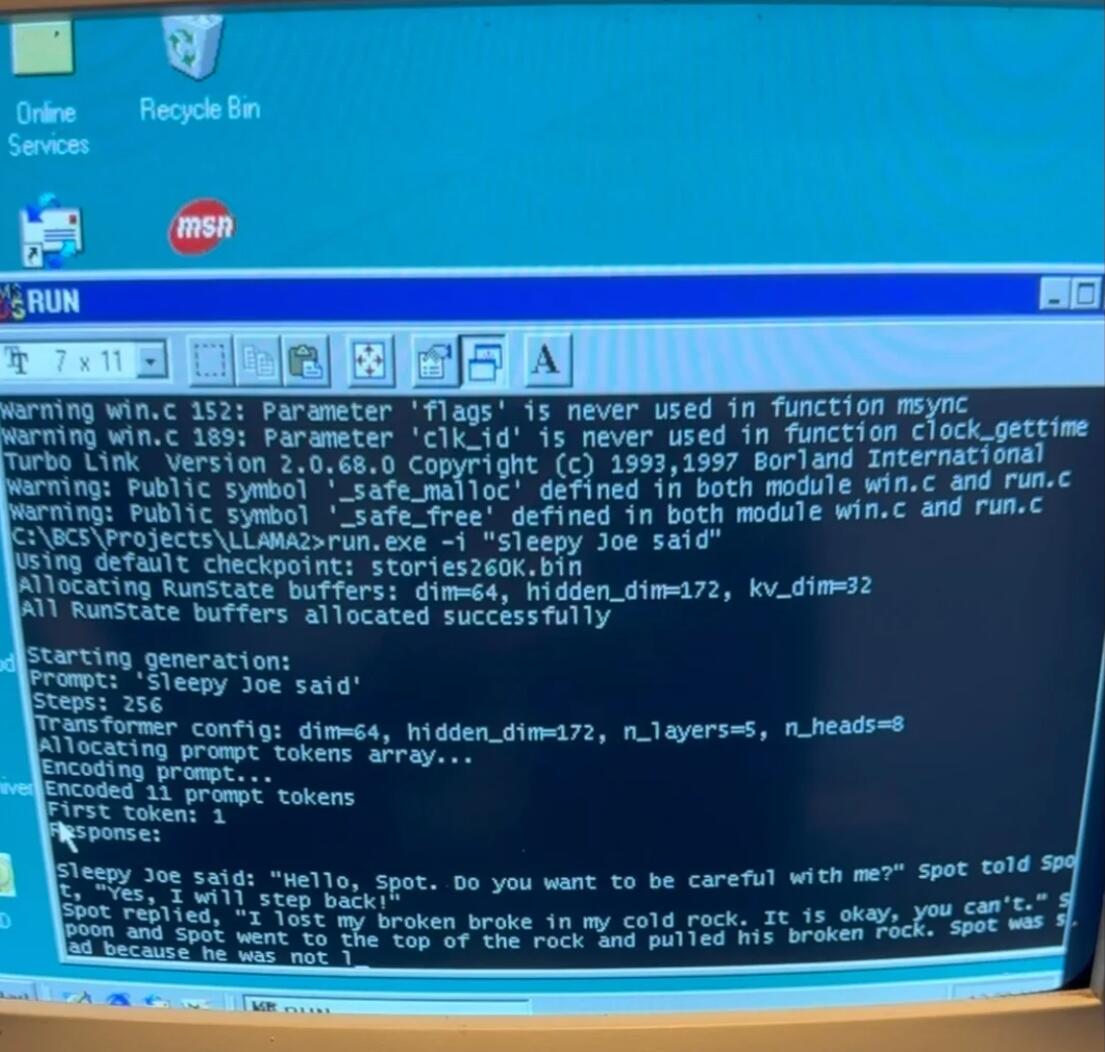
| EXO Labs 最近公开了一段影片,内容是在一个拥有 26年历史的 Windows 98系统、搭载 Pentium II 处理器的电脑上运行大型语言模型(LLM)。这台电脑主频为 350MHz,成功启动并进入 Windows 98 操作系统,之后 EXO Labs 启动了一个基于 Andrej Karpathy 的 Llama2.c 定制的纯C语言推理引擎,并要求 LLM 创作一个关于「Sleepy Joe」的故事,故事生成的速度相当快。
该组织自诩为「民主化AI」的倡导者,由牛津大学的研究人员和工程师组成,他们认为,如果 AI 被少数大型企业所控制,将对文化、真理以及社会的其他基本方面产生不利影响。因此,EXO Labs 致力于构建开放的基础设施,训练前沿的模型,并确保全球各地的任何人都能够运行这些模型。这次在 Windows 98 系统上展示的 AI 演示,证明了即使在资源极为有限的情况下,也能实现的事。
EXO Labs 在其文章中透露了在 Windows 98 系统上运行 Llama 的过程,他们购买了一部旧的 Windows 98 电脑作为项目的基础,但在此过程中遇到了诸多挑战。首先是数据的传输迁移,他们被迫采用「传统的FTP」方法,通过旧式机的 LAN 口进行文件传输。 除此之外,编译现代代码以适应 Windows 98 系统也是一大难题。EXO Labs 找到了 Andrej Karpathy 的llama2.c,这是一个「700行纯C代码,能够运行 Llama 2 架构模型的推理」的解决方案。利用这一资源以及旧版的 Borland C++5.02 IDE和编译器(并进行了一些微调),他们成功地将代码编译成 Windows 98 兼容的可执行文件并成功运行,相关代码可以在 GitHub 上找到链接。 在 Windows 98 系统上,使用 260K LLM 和 Llama 架构,他们实现了「每秒35.9个token」的速度。根据 EXO Labs 的博客,当升级到 15M LLM 后,生成速度略高于每秒1个 token,而 Llama 3.2 1B 的速度则明显较慢,为每秒 0.0093个 token。 |