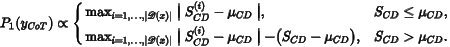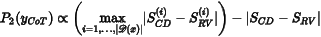作者:蔡文睿(清素)、汪诚愚(熊兮)、严俊冰(玖烛)、黄俊(临在)前言
近年来,自然语言处理(NLP)领域以大语言模型(LLM)的出现为标志,发生了深刻变革,引领了语言理解、生成和推理任务的进步。其中,进步尤其显著的是深度推理模型的发展,如OpenAI的o1、DeepSeek-R1和QwQ-32B等,它们在数学问题、代码生成等复杂推理任务中表现突出。这些模型的成功很大程度上得益于使用思维链(Chain-of-Thought,
CoT)的推理方式,能够模拟人类的渐进思考过程,将复杂问题化繁为简。然而,对于不同的推理任务,使用长思考的推理模式并不能提升模型在所有推理任务上的精度,反而容易引发“过度思考”的问题,既降低了模型响应速度,又导致推理过程中频繁出错。
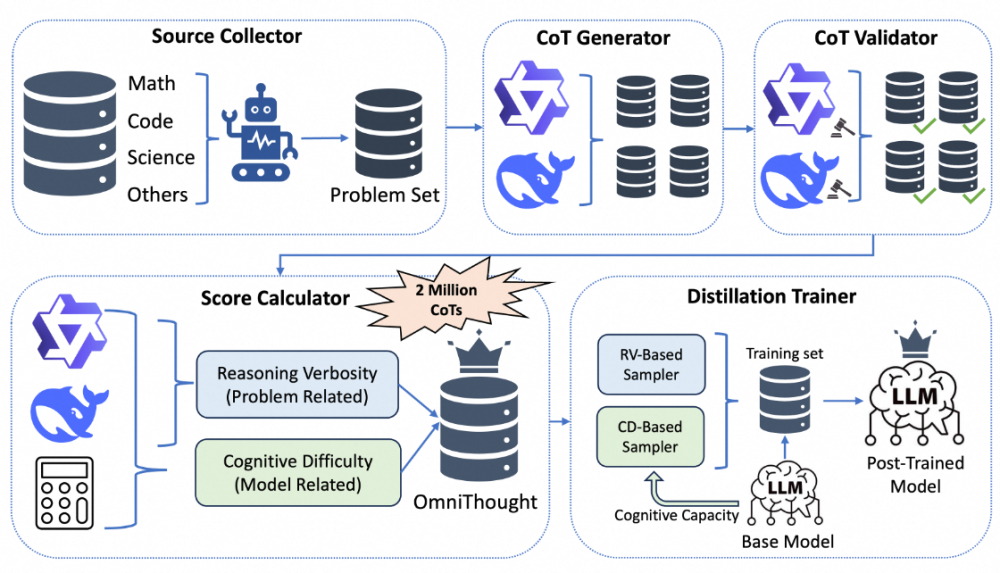
为了便于社区用户使用DistilQwen-ThoughtX系列模型,以及蒸馏适合自身场景的推理模型,我们在EasyDistill(https://github.com/modelscope/easydistill)的框架中开源了OmniThought的全部数据,以及所有DistilQwen-ThoughtX系列模型的权重。在下文中,我们将介绍OmniThought数据集的构建流程和DistilQwen-ThoughtX系列模型的效果。 OmniThought数据集构建
基础数据搜集和正确性验证
接下来,我们使用DeepSeek-R1和
QwQ-32B作为教师模型,为问题集合生成多个思维链推理过程。为了确保生成的思维链过程的高质量,我们进一步采用“LLM-as-a-judge”方法,对生成的思维链进行多个方面的验证,其中包括逻辑正确性及推导出正确答案的能力,模版如下所示: 推理冗余度(Reasoning
Verbosity)
思维链本质上涉及自我反思,促使模型在推理过程中进行多轮反思和修正。这种机制在模型处理复杂问题时有助于降低错误率,却可能导致在简单问题上陷入“过度思考”的情况,例如对“1 + 1 = ?”问题回答进行过度检查。这样的过度思考不仅浪费计算资源,还可能降低推理准确度。因此,对于特定问题,其思维链的长度应与问题的难度相匹配,这反映了思维链的“推理冗余度(Reasoning Verbosity,RV)”,我们对RV分级标准进行了正式定义,采用0到9的评分,具体用于评估RV的模版详见相关论文。 0-1:
最低冗余度,直接输出结果,几乎没有详细说明。
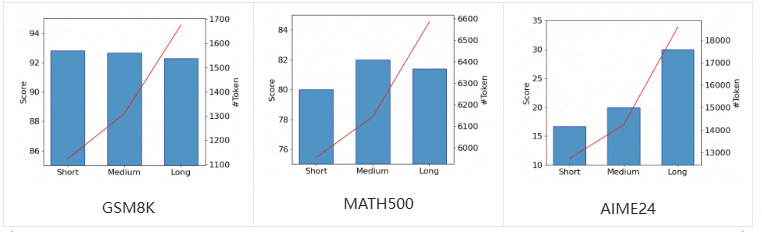
由上图可见,在相对简单的GSM8K任务中,所有模型表现出相似的性能;输出token的增加没有提高准确性,甚至导致轻微下降。在中等难度的MATH500任务上,准确度随着token数的增加而提高,随后下降,其中中等模型在产生适量token数时达到最高的准确度。在最具挑战的AIME24问题中,长模型获得最高分;模型的准确性随着token数的增加而提高。因此,对于难度较大的问题,较长的思维链能够纠正模型自身错误,从而有效提高准确性。然而,在简单任务中,思维链中的过度推理和验证不仅增加了计算资源的消耗,还可能降低问题解决的准确性。所以,我们可以根据任务难度构建具备相应RV级别思维链的训练集,从而最大化计算资源利用,同时确保高准确性。 认知难度(Cognitive Difficulty)
实验结果显示,随着模型参数量的增加,思维链的难度也在上升,这表明较大的模型拥有更强的推理和认知能力。因此,困难的思维链可能不适合训练认知能力较低的模型。因此,使用与模型认知能力一致的思维链来提升其推理能力是至关重要的,这类似于“因材施教”的策略。在我们的工作中,认知难度(Cognitive
Difficulty,CD)分数分级标准如下所示,具体用于评估CD的模版详见相关论文: 0-1:
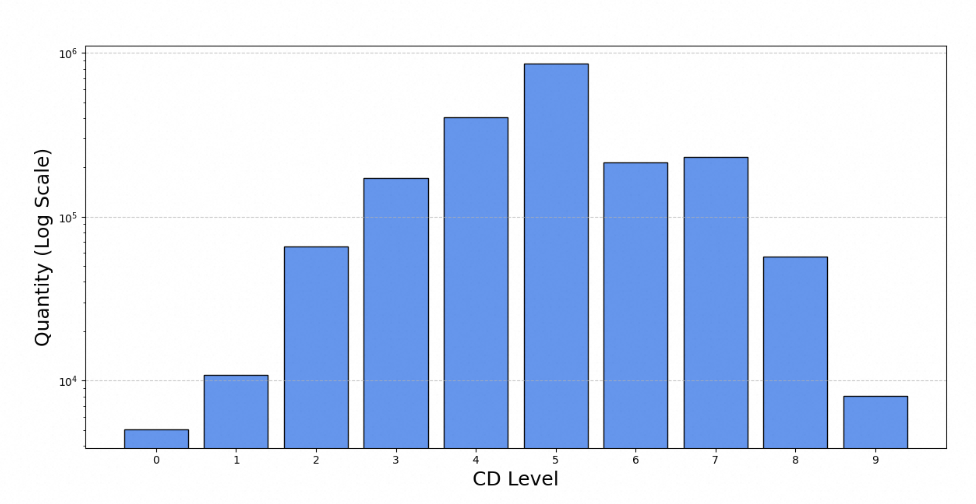
小学、入门级知识,或者单一简单思考模式。 在OmniThought中,我们对所有验证正确的思维链进行评分,CD分布如图所示:
DistilQwen-ThoughtX:变长思维链推理模型
基于我们提出的OmniThought数据集,我们训练了DistilQwen-ThoughtX系列模型,由于我们可以通过RV和CD分数对思维链进行筛选,训练得到的模型获得根据问题和本身的认知能力,生成变长思维链的能力。具体地说,我们设置目标模型的认知能力为
从上面可以看出,我们假设对于CD级别小于等于
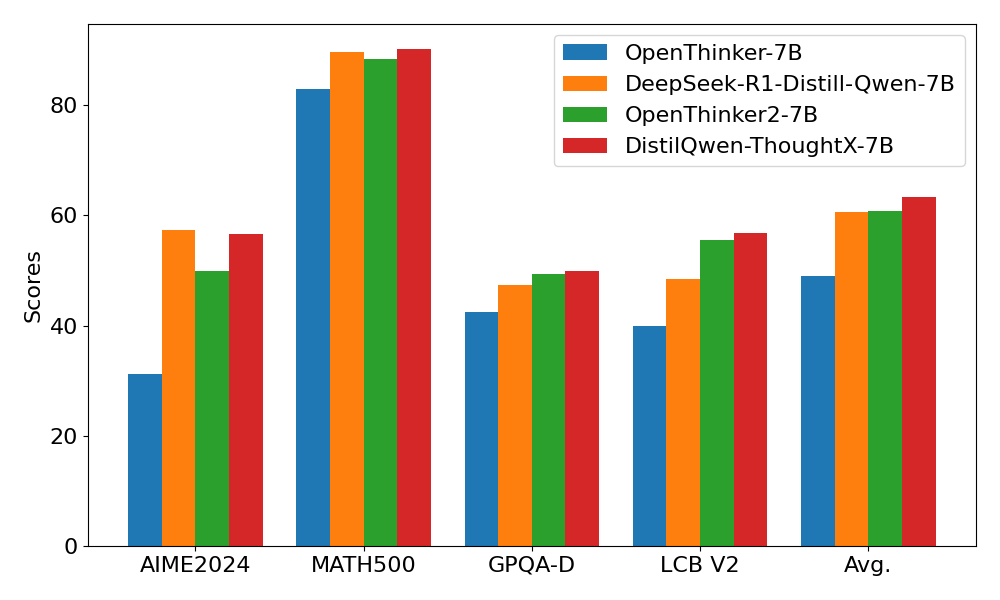
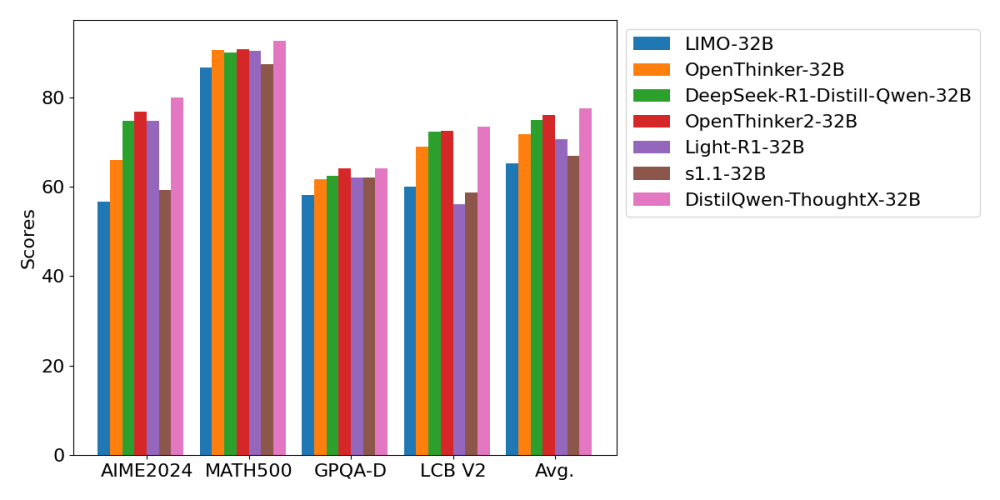
基于上述采样方法,对于OmniThought中的708K个问题,我们抽样出合适的思维链以通过SFT训练模型。我们从Qwen2.5系列(7B和32B)初始化,训练两个模型,分别命名为DistilQwen-ThoughtX-7B和DistilQwen-ThoughtX-32B。我们将我们的模型与开源社区中的知名蒸馏推理模型进行比较,结果汇总见表格。我们观察到,基于OmniThought数据集和我们基于RV-CD的思维链选择策略,我们模型效果优异,表现甚至优于DeepSeek官方采用闭源数据集蒸馏的模型。其中,DistilQwen-ThoughtX (Full)指使用全量思维链数据训练的模型,可以看出使用我们提出的评分和筛选方法训练的模型效果有明显提升。 下表展示了DistilQwen-ThoughtX的性能表现: 开源模型和数据集下载和使用
DistilQwen-ThoughtX在开源社区的下载
我们在Hugging Face和Model Scope上开源了我们蒸馏后的模型,分别为DistilQwen-ThoughtX-7B、DistilQwen-ThoughtX-32B。以Hugging Face为例,用户可以使用如下代码下载这两个模型: OmniThought数据集在开源社区的下载
我们在Hugging Face和Model Scope上开源了我们的数据集OmniThought。以Hugging Face为例,用户可以使用如下代码下载这两个模型: 本文小结
近年来,随着大语言模型的出现,自然语言处理领域发生了重要变革,其中深度推理模型在复杂推理任务中表现尤为突出。然而,长思维链推理可能导致“过度思考”,影响模型性能。为解决此问题,阿里云PAI团队开发了OmniThought数据集,其中包含200万思维链,并标注了推理冗余度(RV)和认知难度(CD)分数。这使得模型能够根据任务自适应选择思维链长度,从而提升其推理能力。基于此数据集,我们推出了DistilQwen-ThoughtX系列模型,这些模型在性能上超过了DeepSeek-R1-Distill系列。为了支持社区用户使用及优化这些模型,我们在EasyDistill框架中开源了OmniThought数据集和DistilQwen-ThoughtX模型的全部权重。在未来,我们将进一步基于EasyDistill框架开源更多DistilQwen模型系列和相应资源。欢迎大家加入我们,一起交流大模型蒸馏技术! 参考工作
·
DistilQwen2.5发布:通义千问蒸馏小模型再升级 ·
DistilQwen2.5-R1发布:知识蒸馏助推小模型深度思考 ·
人工智能平台 PAI
DistilQwen2.5-DS3-0324发布:知识蒸馏+快思考=更高效解决推理难题 联系我们
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||